Attention: to whom interested in Integrating privacy into data equations.

Fundamentals
Since the revolution of the internet and the advancement of AI, it has become evident that data is a valuable resource. Many giant corporations strive to collect as much data as possible, often boasting about their data processing capabilities. The more data they can process, the more valuable their companies become. However, the fact is that data has always been a valuable resource; the public has only recently come to understand its real value. In the 2010s, personal data belonging to millions of Facebook users was collected without their consent by the British consulting firm Cambridge Analytica, primarily for use in political advertising (Rosalie, 2019).
This incident has highlighted the importance of privacy when handling data and has revealed more about the curators entrusted with public data. In the field of privacy and security research, the current focus appears to be on further advancements in protecting data privacy and enhancing security measures.
This article introduces a new method called “DisguiseData.” This introduction precedes the publication of the academic paper, where the author will delve into the mathematical intuition and more in-depth analysis. However, the introduction will present the general concept and showcase the method’s implementation. The following sections are organized as follows: initially, it will discuss the relationship between data and AI, then it will list the most recent techniques applied for data privacy. Following that, it will introduce the method, and finally, it will share the results of the implementation.
Data, Privacy, and AI
There seems to be a misunderstanding about the meaning of privacy, which is often confused with security. Privacy and security are distinct terms and fields of research. However, one conclusion the author of this article assumes is that strong security is most likely built upon a framework that has considered privacy as a factor for the data. While this work does not focus on security, it was important to clarify this aspect.
Data, in its abstract definition, is a value resulting from a measurement. For instance, a person’s age is a data entry measured using a calendar. Similarly, a person’s character traits, such as being strong or weak, are data entries measured by emotional instruments. Misunderstandings about data often arise with bulk entries. For example, is a person’s voice considered data? The answer depends on the context. This type of data entry is known as unstructured data. Unlike structured data, such as a single entry, voice data represents a wave signal. However, technically, it is possible to convert that wave into a series with a certain length. An instrument can then be designed to quantify features of that series, such as depth and frequency. The result of applying such an instrument can define a person’s voice as loud, low, strong, weak, etc. In conclusion, the technical definition of data is a numerical representation of things. This numerical representation can be structured, like rational datasets, or unstructured, like voice or text data.
The final numerical representation of data is crucial as an input for machine learning (ML) and artificial intelligence (AI). AI’s impressive outcomes heavily depend on data. When data is measured, collected, and structured appropriately, the results produced by AI agents tend to be highly accurate. For an in-depth understanding of the AI paradigm and workflow, refer to (Deniz Dahman, Prediction from the Start to the End, 2023).
It’s clear that data can be personal property, and AI models are typically owned by companies or corporations. This means the owners of AI agents might have access to data that belongs to individuals. The challenge arises when this data is sensitive or personal, raising concerns about privacy and data protection. the question then is what can be done to factor privacy into the equation?
Recent Techniques for Data Privacy
Ensuring data privacy is crucial in today’s digital age. Over the years, various technical techniques have been proposed to protect data privacy. Here are some key methods:
- Anonymization, while not a completely new method for preserving privacy, has seen several enhancements over time. Initially, the simplest form of anonymization was to remove identifying features, such as names. However, data breaches have shown that other features can also be sensitive and capable of identifying individuals, as demonstrated by linkage attacks. Consequently, enhancements like k-anonymity, l-diversity, and t-closeness have been introduced. These improvements significantly enhance privacy but are only considered effective when the dataset is queried for statistical purposes. Once the data needs to be shared, these techniques may not be as useful.
- Restricted queries, this technique involve setting specific rules on the query format of a dataset. However, some data breach methods, such as predefined questions, can bypass these rules. Despite this, restricted queries can still be useful when querying a dataset.
- Encryption ensures that only authorized parties can access data. This includes end-to-end encryption for communications and data-at-rest encryption for stored data. Several algorithms have been discussed in the literature: secure multiparty computation (SMPC), private set intersection (PSI), private information retrieval (PIR), zero-knowledge proofs (ZKP), and fully homomorphic encryption (FHE). The latter is particularly prominent in discussions, but a significant drawback of encryption is its time and space complexity. That being said, such a technique seems to work well when the dataset is shared for any purpose.
- Federated Learning is a technique based on the idea that data does not have to leave the owner’s premises. Instead of sending the client’s data to the AI algorithm, the mathematical function of the AI algorithm is sent to the client. While this technique is useful for training AI models without moving data, there are concerns about privacy, such as AI models potentially memorizing specific feature values. Additionally, there are technical requirements to consider when applying this method.
- Differential privacy is one of the most prominent techniques discussed today. It is applied in scenarios where data is either queried or shared. Its prominence is likely due to the mathematical representation of privacy issues related to data. Various methods are used to implement the framework of differential privacy, often based on the type of data feature. For example, noise can be added to numerical features, or randomized response can be applied to categorical data. Despite these methods, there are still numerous challenges and further research is needed to advance this framework.
- Data masking and pseudonymization are techniques used to protect privacy by altering data while preserving its utility. Data masking replaces sensitive information with fictional data, whereas pseudonymization replaces identifiable information with pseudonyms. The proposed method in the article “DisguiseData” falls within this framework.
Lastly, there are practices and workflow regulations applied as well. For instance, implementing strict access controls ensures that only authorized individuals can access sensitive data. Additionally, integrating privacy into the design of systems and processes from the outset, rather than as an afterthought, is crucial. Regular audits and continuous monitoring help detect and respond to data breaches and unauthorized access. Finally, user awareness, education, and compliance with regulations are essential.
To conclude, these techniques and practices, when combined, can significantly enhance data privacy and protect against unauthorized access and data breaches. A detailed survey on data, privacy, and AI can be found in (Deniz Dahman, Review of Data Privacy Techniques: Concepts, Scenarios and Architectures, Simulations, Challenges, and Future Directions, 2024).
The Proposed Method “DisguisedData”
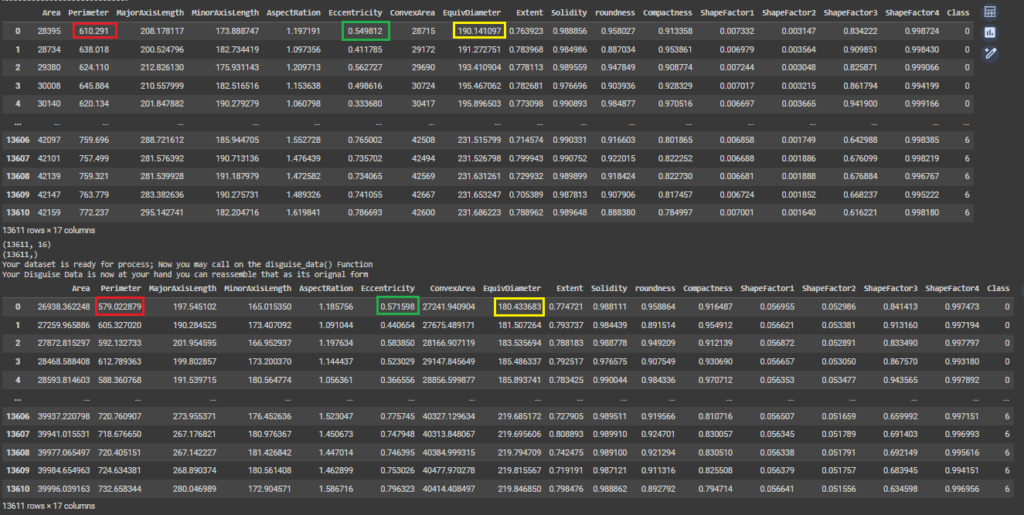
The main principle of the proposed method revolves around two key elements: the norm and the statistical structure of the dataset. The first element represents the total squared sum of each entry in the dataset, which gives the weight of each feature’s range combined with every other feature. This value is crucial for scaling the dataset. The “DisguiseData” method uses this value to scale the dataset and as a secret key to reverse the scaled data.
The second key element involves statistical values such as mean, variance, covariance, and correlation, which are essential for defining the hidden structure of the dataset. These values serve as a baseline for any use of the dataset. The outcome of these two elements is used as input to the mathematical equation proposed by this method. The result is a new set that has the same size as the input set. Using the norm from the first key element can unlock this new dataset, where values within the same range as the original dataset are seen. These new values are different from the original dataset but retain all the common properties of the original one.
This new dataset can be shared, queried, or used as a training dataset for AI models, safeguarding the original data and preserving privacy. What differentiates this method from other similar ones for generating synthetic or disguised data is its light and quick implementation, as conceived in the mathematical representation of the method. To apply this method, there are two main parameters: the mu parameter and the deviation parameter. Detailed mathematical intuition and implementation details can be found in the academic publication of the method, and the implementation can be accessed from the Python package and GitHub (Deniz Dahman, disguisedata 1.0.3 Documentation, 2024; Deniz Dahman, disguisedata 1.0.3, 2024).
Results from implementing the proposed method
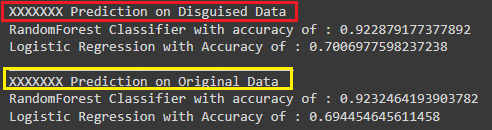
Here are the figures representing the results of implementing the proposed method. The documentation of the results can be found in source (Deniz Dahman, disguisedata 1.0.3 Documentation, 2024)
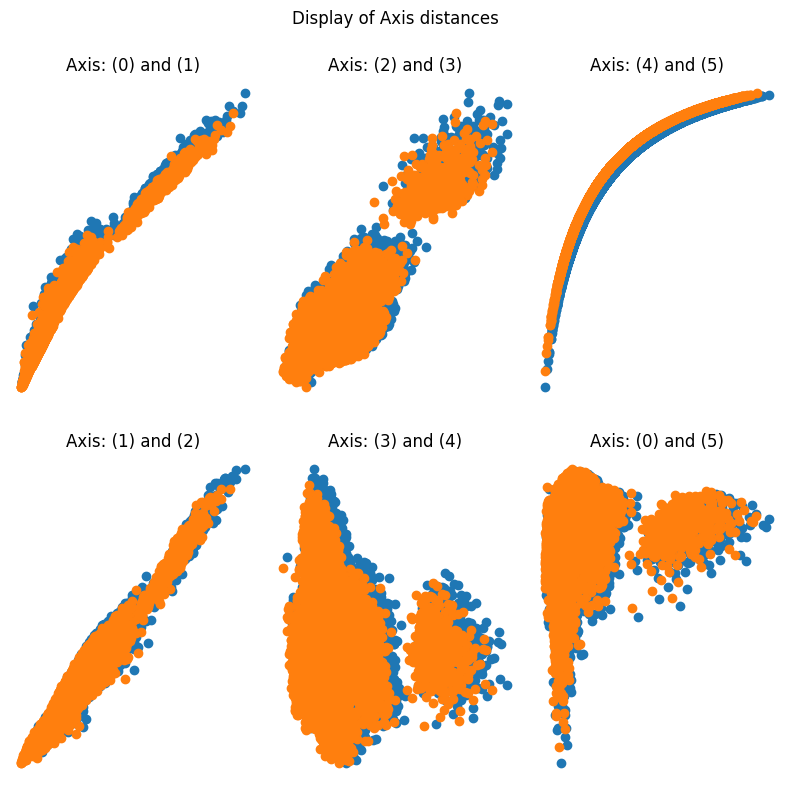
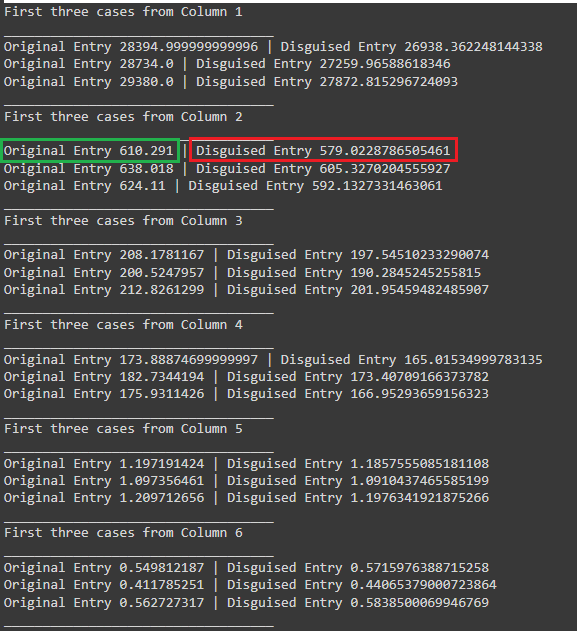
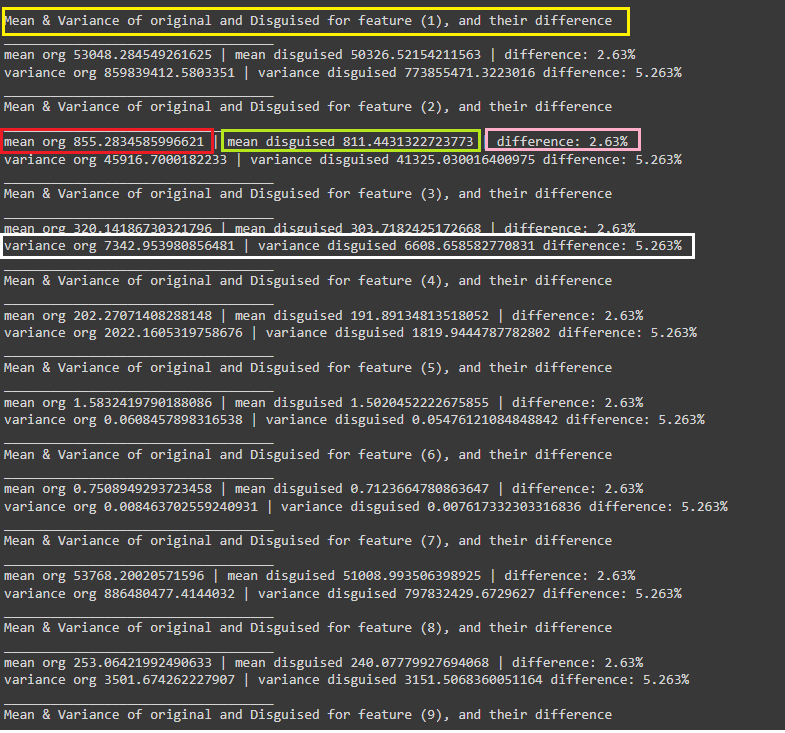

Conclusion
This article introduces a new method to disguise data, i.e. generating synthetic data from original one. The method relies on two key elements: the norm and the statistical structure of the dataset. Results of applying the proposed method shows a huge similarity of values and outcomes once the dataset is used for any purpose such as query or prediction. Further reading on the mathematical intuition of the method can be sought from the academic publication, and for testing the creator of the method authored a Python package that can be used for that purpose.
References
Deniz Dahman. (2023). Prediction from the Start to the End. The Big Bang of Data Science. (1, Ed.) Istanbul, Türkiey: GitHub Repoisitory. Retrieved from https://github.com/dahmansphi/prediction_from_start_to_end
Deniz Dahman. (2024). disguisedata 1.0.3. A tiny tool for generating synthetic data from the original one. PyPi. Retrieved from https://pypi.org/project/disguisedata/
Deniz Dahman. (2024). disguisedata 1.0.3 Documentation. DisguiseData Method- Full Guide. GitHub Repository. Retrieved from https://github.com/dahmansphi/disguisedata
Deniz Dahman. (2024). Review of Data Privacy Techniques: Concepts, Scenarios and Architectures, Simulations, Challenges, and Future Directions. ScienceOpen Preprints. doi:10.14293/PR2199.000936.v1
Rosalie, C. (2019, 10). “The Cambridge Analytica whistleblower explains how the firm used Facebook data to sway elections”. Retrieved from Business Insider.: https://www.businessinsider.com/cambridge-analytica-whistleblower-christopher-wylie-facebook-data-2019-10